%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Diffusion Transformer
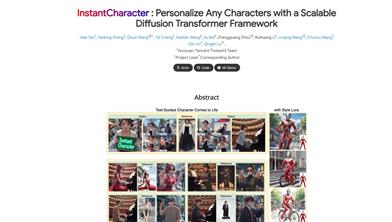
Instantcharacter
InstantCharacter is a character personalization framework based on diffusion transformers, designed to overcome the limitations of existing learning-based customization methods. The framework's main advantages lie in its open-domain personalization, high-fidelity results, and effective character feature processing capabilities, suitable for generating various character appearances, poses, and styles. The framework utilizes a large-scale dataset containing tens of millions of samples for training to achieve both character consistency and text editability optimization. This technology sets a new benchmark for character-driven image generation.
AI Color Generation
38.6K

Easycontrol
EasyControl is a framework that provides efficient and flexible control for Diffusion Transformer (DiT), aiming to solve the efficiency bottlenecks and lack of model adaptability in the current DiT ecosystem. Its main advantages include: supporting multiple conditional combinations, improving generation flexibility and inference efficiency. This product is developed based on the latest research results and is suitable for use in image generation, style transfer, and other fields.
AI Model
38.6K

Ditctrl
DiTCtrl is a video generation model based on the Multimodal Diffusion Transformer (MM-DiT) architecture, focusing on generating coherent scene videos with multiple continuous prompts without additional training. By analyzing the attention mechanism of MM-DiT, this model achieves precise semantic control and attention sharing between different prompts, producing videos with smooth transitions and cohesive object movement. The main advantages of DiTCtrl include no training requirement, capability to handle multi-prompt video generation tasks, and showcasing cinematic transition effects. Additionally, DiTCtrl introduces a new benchmark called MPVBench specifically designed for evaluating the performance of multi-prompt video generation.
Video Production
46.1K
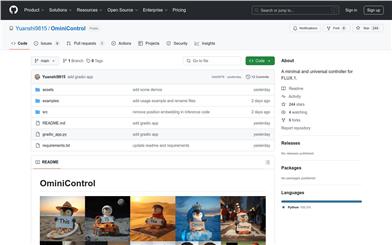
Ominicontrol
OminiControl is a minimal yet powerful universal control framework designed for diffusion transformer models like FLUX. It supports subject-driven control and spatial tasks (such as edge guidance and image restoration). The design of OminiControl is extremely streamlined, introducing only 0.1% additional parameters to the base model while retaining the original model structure. This project is developed by the Learning and Vision Laboratory at the National University of Singapore, representing the latest advancements in image generation and control technologies in the field of artificial intelligence.
Image Generation
75.6K
Fresh Picks
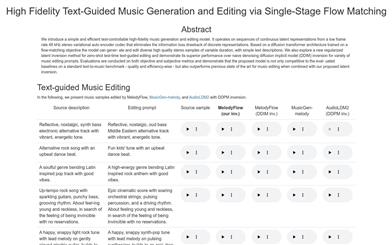
Melodyflow
MelodyFlow is a high-fidelity music generation and editing model based on text control. It utilizes continuous latent representation sequences to avoid information loss associated with discrete representations. Built on a diffusion transformer architecture and trained with flow matching objectives, the model can generate and edit a diverse range of high-quality stereo samples while maintaining the simplicity of text descriptions. MelodyFlow also explores a novel regularized latent inversion method for text-guided editing in zero-shot testing, demonstrating its superior performance across various music editing prompts. The model has been evaluated using objective and subjective metrics, confirming that it matches the quality and efficiency of established benchmarks in standard text-to-music evaluations while surpassing previous state-of-the-art techniques in music editing.
Music Generation
46.9K
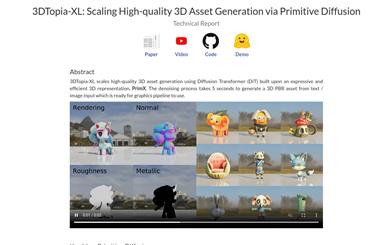
3dtopia XL
3DTopia-XL is a high-quality 3D asset generation technology built on the Diffusion Transformer (DiT), utilizing a novel 3D representation method called PrimX. This technology encodes 3D shapes, textures, and materials into a compact N x D tensor, where each element represents a volumetric primitive anchored to the surface of the shape, encoding signed distance fields (SDF), RGB, and materials through voxelized payloads. This process generates 3D PBR assets from text/image inputs in just 5 seconds, suitable for graphics pipelines.
AI image generation
52.2K
Qihoo T2X
Qihoo-T2X is an open-source project developed by 360CVGroup, representing an innovative paradigm of diffusion transformer (DiT) architecture for text-to-any-task (Text-to-Any). The project aims to enhance processing efficiency through proxy token technology. Qihoo-T2X is an ongoing project, with a team committed to continuously optimizing and enhancing its functionalities.
AI Model
50.5K
Fresh Picks

Tora
Tora is a video generation model based on Diffusion Transformers (DiT), which integrates text, visual, and trajectory conditions to achieve precise control over video content dynamics. Tora is designed to fully leverage the scalability of DiT, allowing for the generation of high-quality video content across different durations, aspect ratios, and resolutions. The model excels in motion fidelity and physical world motion simulation, offering new possibilities for video content creation.
AI video generation
135.2K

PIXART
PIXART-Σ is a diffusion transformer model that directly generates 4K resolution images. Compared to its predecessor PixArt-α, it offers higher image fidelity and better alignment with text prompts. The key features of PIXART-Σ include an efficient training process, where it evolves from a 'weaker' baseline model to a 'stronger' model by leveraging higher-quality data in a process called 'weak-to-strong training'. Improvements in PIXART-Σ include the use of higher-quality training data and efficient label compression.
AI image generation
483.6K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M